Join Transform 2021 for the most important themes in enterprise AI & Data. Learn more.
This article is part of our reviews of AI research papers, a series of posts that explore the latest findings in artificial intelligence.
There’s a growing interest in employing autonomous mobile robots in open work environments such as warehouses, especially with the constraints posed by the global pandemic. And thanks to advances in deep learning algorithms and sensor technology, industrial robots are becoming more versatile and less costly.
But safety and security remain two major concerns in robotics. And the current methods used to address these two issues can produce conflicting results, researchers at the Institute of Science and Technology Austria, the Massachusetts Institute of Technology, and Technische Universitat Wien, Austria have found.
On the one hand, machine learning engineers must train their deep learning models on many natural examples to make sure they operate safely under different environmental conditions. On the other, they must train those same models on adversarial examples to make sure malicious actors can’t compromise their behavior with manipulated images.
But adversarial training can have a significantly negative impact on the safety of robots, the researchers at IST Austria, MIT, and TU Wien discuss in a paper titled “Adversarial Training is Not Ready for Robot Learning.” Their paper, which has been accepted at the International Conference on Robotics and Automation (ICRA 2021), shows that the field needs new ways to improve adversarial robustness in deep neural networks used in robotics without reducing their accuracy and safety.
Adversarial training
Deep neural networks exploit statistical regularities in data to carry out prediction or classification tasks. This makes them very good at handling computer vision tasks such as detecting objects. But reliance on statistical patterns also makes neural networks sensitive to adversarial examples.
An adversarial example is an image that has been subtly modified to cause a deep learning model to misclassify it. This usually happens by adding a layer of noise to a normal image. Each noise pixel changes the numerical values of the image very slightly, enough to be imperceptible to the human eye. But when added together, the noise values disrupt the statistical patterns of the image, which then causes a neural network to mistake it for something else.
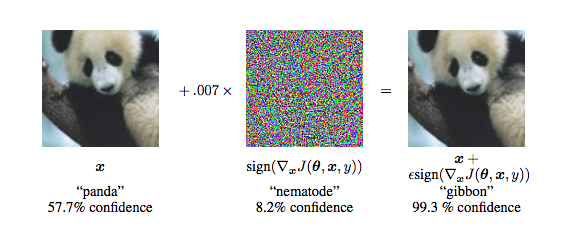
Above: Adding a layer of noise to the panda image on the left turns it into an adversarial example.
Adversarial examples and attacks have become a hot topic of discussion at artificial intelligence and security conferences. And there’s concern that adversarial attacks can become a serious security concern as deep learning becomes more prominent in physical tasks such as robotics and self-driving cars. However, dealing with adversarial vulnerabilities remains a challenge.
One of the best-known methods of defense is “adversarial training,” a process that fine-tunes a previously trained deep learning model on adversarial examples. In adversarial training, a program generates a set of adversarial examples that are misclassified by a target neural network. The neural network is then retrained on those examples and their correct labels. Fine-tuning the neural network on many adversarial examples will make it more robust against adversarial attacks.
Adversarial training results in a slight drop in the accuracy of a deep learning model’s predictions. But the degradation is considered an acceptable tradeoff for the robustness it offers against adversarial attacks.
In robotics applications, however, adversarial training can cause unwanted side effects.
“In a lot of deep learning, machine learning, and artificial intelligence literature, we often see claims that ‘neural networks are not safe for robotics because they are vulnerable to adversarial attacks’ for justifying some new verification or adversarial training method,” Mathias Lechner, Ph.D. student at IST Austria and lead author of the paper, told TechTalks in written comments. “While intuitively, such claims sound about right, these ‘robustification methods’ do not come for free, but with a loss in model capacity or clean (standard) accuracy.”
Lechner and the other coauthors of the paper wanted to verify whether the clean-vs-robust accuracy tradeoff in adversarial training is always justified in robotics. They found that while the practice improves the adversarial robustness of deep learning models in vision-based classification tasks, it can introduce novel error profiles in robot learning.
Adversarial training in robotic applications

Say you have a trained convolutional neural network and want to use it to classify a bunch of images stored in a folder. If the neural network is well trained, it will classify most of them correctly and might get a few of them wrong.
Now imagine that someone inserts two dozen adversarial examples in the images folder. A malicious actor has intentionally manipulated these images to cause the neural network to misclassify them. A normal neural network would fall into the trap and give the wrong output. But a neural network that has undergone adversarial training will classify most of them correctly. It might, however, see a slight performance drop and misclassify some of the other images.
In static classification tasks, where each input image is independent of others, this performance drop is not much of a problem as long as errors don’t occur too frequently. But in robotic applications, the deep learning model is interacting with a dynamic environment. Images fed into the neural network come in continuous sequences that are dependent on each other. In turn, the robot is physically manipulating its environment.

“In robotics, it matters ‘where’ errors occur, compared to computer vision which primarily concerns the amount of errors,” Lechner says.
For instance, consider two neural networks, A and B, each with a 5% error rate. From a pure learning perspective, both networks are equally good. But in a robotic task, where the network runs in a loop and makes several predictions per second, one network could outperform the other. For example, network A’s errors might happen sporadically, which will not be very problematic. In contrast, network B might make several errors consecutively and cause the robot to crash. While both neural networks have equal error rates, one is safe and the other isn’t.
Another problem with classic evaluation metrics is that they only measure the number of incorrect misclassifications introduced by adversarial training and don’t account for error margins.
“In robotics, it matters how much errors deviate from their correct prediction,” Lechner says. “For instance, let’s say our network misclassifies a truck as a car or as a pedestrian. From a pure learning perspective, both scenarios are counted as misclassifications, but from a robotics perspective the misclassification as a pedestrian could have much worse consequences than the misclassification as a car.”
Errors caused by adversarial training
The researchers found that “domain safety training,” a more general form of adversarial training, introduces three types of errors in neural networks used in robotics: systemic, transient, and conditional.
Transient errors cause sudden shifts in the accuracy of the neural network. Conditional errors will cause the deep learning model to deviate from the ground truth in specific areas. And systemic errors create domain-wide shifts in the accuracy of the model. All three types of errors can cause safety risks.

Above: Adversarial training causes three types of errors in neural networks employed in robotics.
To test the effect of their findings, the researchers created an experimental robot that is supposed to monitor its environment, read gesture commands, and move around without running into obstacles. The robot uses two neural networks. A convolutional neural network detects gesture commands through video input coming from a camera attached to the front side of the robot. A second neural network processes data coming from a lidar sensor installed on the robot and sends commands to the motor and steering system.
The researchers tested the video-processing neural network with three different levels of adversarial training. Their findings show that the clean accuracy of the neural network decreases considerably as the level of adversarial training increases. “Our results indicate that current training methods are unable to enforce non-trivial adversarial robustness on an image classifier in a robotic learning context,” the researchers write.

Above: The robot’s visual neural network was trained on adversarial examples to increase its robustness against adversarial attacks.
“We observed that our adversarially trained vision network behaves really opposite of what we typically understand as ‘robust,’” Lechner says. “For instance, it sporadically turned the robot on and off without any clear command from the human operator to do so. In the best case, this behavior is annoying, in the worst case it makes the robot crash.”
The lidar-based neural network did not undergo adversarial training, but it was trained to be extra safe and prevent the robot from moving forward if there was an object in its path. This resulted in the neural network being too defensive and avoiding benign scenarios such as narrow hallways.
“For the standard trained network, the same narrow hallway was no problem,” Lechner said. “Also, we never observed the standard trained network to crash the robot, which again questions the whole point of why we are doing the adversarial training in the first place.”
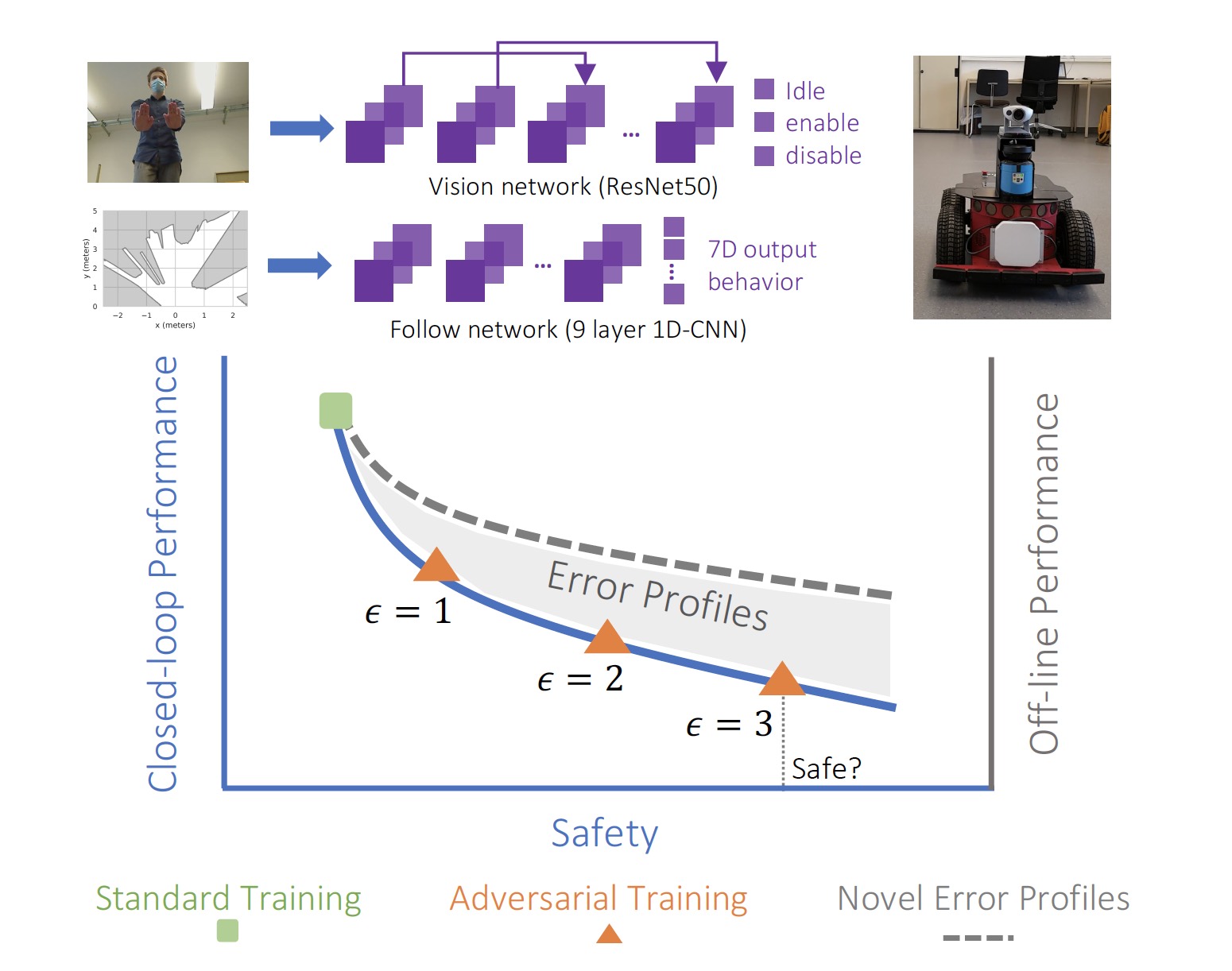
Above: Adversarial training causes a significant drop in the accuracy of neural networks used in robotics.
Future work on adversarial robustness
“Our theoretical contributions, although limited, suggest that adversarial training is essentially re-weighting the importance of different parts of the data domain,” Lechner says, adding that to overcome the negative side-effects of adversarial training methods, researchers must first acknowledge that adversarial robustness is a secondary objective, and a high standard accuracy should be the primary goal in most applications.
Adversarial machine learning remains an active area of research. AI scientists have developed various methods to protect machine learning models against adversarial attacks, including neuroscience-inspired architectures, modal generalization methods, and random switching between different neural networks. Time will tell whether any of these or future methods will become the golden standard of adversarial robustness.
A more fundamental problem, also confirmed by Lechner and his coauthors, is the lack of causality in machine learning systems. As long as neural networks focus on learning superficial statistical patterns in data, they will remain vulnerable to different forms of adversarial attacks. Learning causal representations might be the key to protecting neural networks against adversarial attacks. But learning causal representations itself is a major challenge and scientists are still trying to figure out how to solve it.
“Lack of causality is how the adversarial vulnerabilities end up in the network in the first place,” Lechner says. “So, learning better causal structures will definitely help with adversarial robustness.”
“However,” he adds, “we might run into a situation where we have to decide between a causal model with less accuracy and a big standard network. So, the dilemma our paper describes also needs to be addressed when looking at methods from the causal learning domain.”
Ben Dickson is a software engineer and the founder of TechTalks. He writes about technology, business, and politics.
This story originally appeared on Bdtechtalks.com. Copyright 2021
VentureBeat
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative technology and transact. Our site delivers essential information on data technologies and strategies to guide you as you lead your organizations. We invite you to become a member of our community, to access:
- up-to-date information on the subjects of interest to you
- our newsletters
- gated thought-leader content and discounted access to our prized events, such as Transform 2021: Learn More
- networking features, and more



